Our Google Summer of Code students presented their work at a special edition of the community call yesterday. You can catch up on the entire recording on YouTube – or scroll down to see individual presentations. The agenda and notes accompanying the call (including code and slides links) is in Google Docs.
After weeks and weeks of fabulous work, our six Google Summer of Code projects are approaching the finish line. As in previous years (2018, 2017), our students will be sharing their work in a series of 5-minutes presentations at an InterMine Community Call. Everyone from the InterMine community is encouraged to come and see what our fantastic students have been up to.
Joining the call
The call will be on the 14th of August 2019. (Note we previously advertised the call as being on the 15th; this was an error – the call is definitely on Wednesday the 14th of August).
One of the goals of Google Summer of Code (GSoC) is to help turn students into long-term open source maintainers and contributors. I suspect we’ve managed this with our current batch of students, who have contributed to our projects across a broad range of topics, whether it was querying InterMine using natural language sentences, updating our search capabilities (both UIs and search backends), or adding new features to the InterMine python client.
From the start of the application process, our fabulous pool of applicants spent time interacting with each other and even helping each other out before anyone had been officially accepted. We received numerous PRs, tickets, and suggestions on our GitHub repos, and for this year we had returning GSoC mentors who previously had been students. It’s almost hard to believe we hadn’t participated before 2017, seeing all of the great work and enthusiasm GSoC brings, all while being able to pay students for their time and give them valuable work experience.
To wrap up this year’s great set of projects we had a community call [agenda & notes here] where our students presented their work in roughly 5 minute slots. You can catch up on each of the recorded presentations in our GSoC 2018 playlist, or here are direct links to each of the videos:
Currently InterMine uses Apache Lucene (v3.0.2) library to index the data and provide a key-word style search over all data. The goal of this project is to introduce Apache Solr in InterMine so that indexing and searching can happen even quicker. Unlike Lucene which is a library, Apache Solr is a separate server application which is similar to a database server. We setup and configure Solr (v.7.2.1) independently from the application. We use Solr clients to communicate between the application and the Solr instance.
Here, SolrJ (v.7.2.1), a java client for solr is used to communicate between the InterMine and Solr. We also removed the bobo facet library which is used with Lucene since Solr itself provides faceted search. The implementations has been designed in a manner that InterMine would not be heavily coupled with Solr. When you want to change your search engine to something else in future, you just have make different implementations for the interfaces defined.
Currently the search index and the autocomplete index processes use Solr to index the data. The index time has improved significantly with compared to previous indexing times. For example, currently FlyMine takes around around 1900 seconds (32 mins) to index the data. But with Solr we see that it takes only 1250 seconds (21 mins) which is 34% reduction in time. Query time has also improved with Solr where a query of “*:*” in FlyMine would take around 30-40 seconds which with Solr takes less than 1 second. Previously with Lucene, the indexed data has to be retrieved from the database during the first search after starting the webapp. This took some time but with Solr, it is not the case and the results are instantly returned.
Addition to the above, two web services have been implemented. A Facet service has been implemented which will return only the facet counts for a particular query rather than returning all the results. The other web service is Facet List service which is similar to the previous one but it will return all the facets available in a mine. It will be useful when you want to know all the facets in a mine before you run an actual search.
All these changes are made against InterMine 2.0 version. These changes will be included in an InterMine release in near future, but for those who want to try these changes immediately, can checkout this branch in Github and follow these instructions. All these changes are tested with Apache Solr (v7.2.1).
The GSoC 2018 is coming to its end, and after 3 months of hard work, I can proudly present a summary of all our achievements during this summer of code.
Summary of Project Goals
InterMine is a open source Data Warehouse intended to be used for the integration and analysis of complex biological data. With InterMine, you can explore organism and other research data provided by different organizations, moving between databases using criteria such as homology.
The existing query builder in InterMine requires some experience to obtain the desired data in a mine, which can become overwhelming for new users. For instance, for a user interested on searching data in HumanMine using its query builder, he or she would need to browse through the different classes and attributes, choosing between the available fields and adding the different constraints over each of them, in order to get the desired output.
For example, a simple query you might want to glean from InterMine might be as follows:
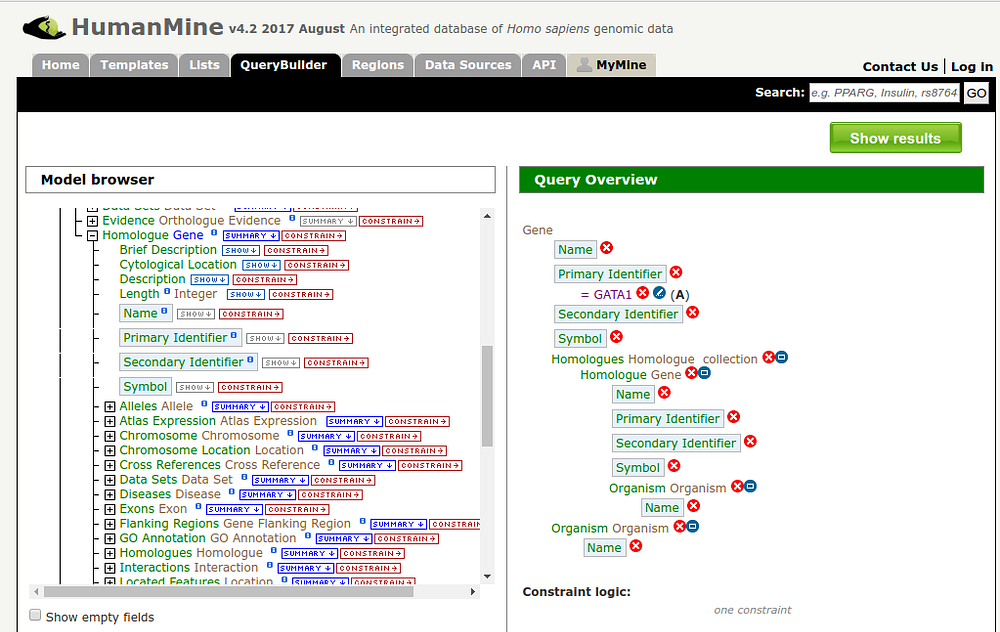
Problem: This query sounds simple-ish, but building it in our query builder requires a strong familiarity with the data model, and can be confusing for anyone new to InterMine. We would like the data browser to be more complex than the simplicity of a simple keyword search, but less complex than the current query builder. For context, here’s the humanmine query builder: http://www.humanmine.org/humanmine/customQuery.do. We have attached a screenshot of what it looks like for the homology query mentioned above, where it can be seen why it looks a little intimidating.
This requires the user to have a decent knowledge of the model schema in order to successfully build a correct query for the expected query results. For new users this workflow can become, indeed, overwhelming to search for specific information in the data.
For this reason the goal of this project is to implement a faceted search tool to display the data from InterMine database, allowing the users to search easily within the different mines available around InterMine, without the requirement of having an extensive knowledge of the data model.
Summary of Project Achievements
In order to maintain a good workflow, the project was divided into three major versions or milestones, coinciding the deadline of each one with GSoC evaluation phases. The main developments in each milestone are listed below, and comprises a total of 67 closed issues with 194 commits.
Milestone 1 (June 11). In the first milestone (related GitHub issue here), the following features were added:
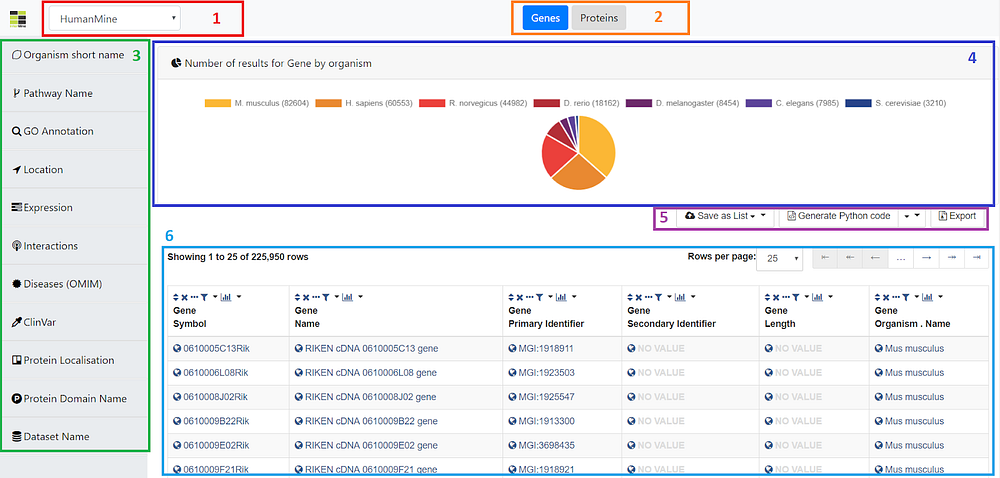
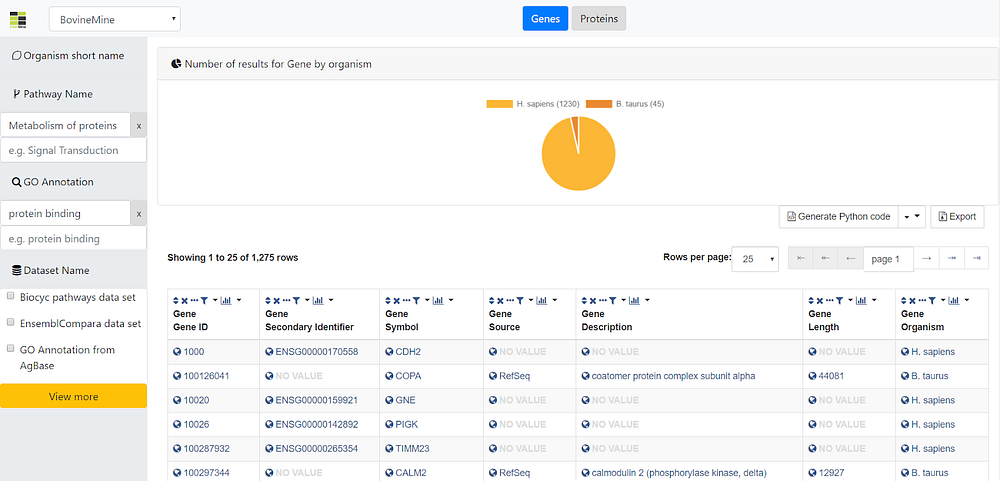
In the following figure, the different elements available on the browser interface are displayed and further explained.
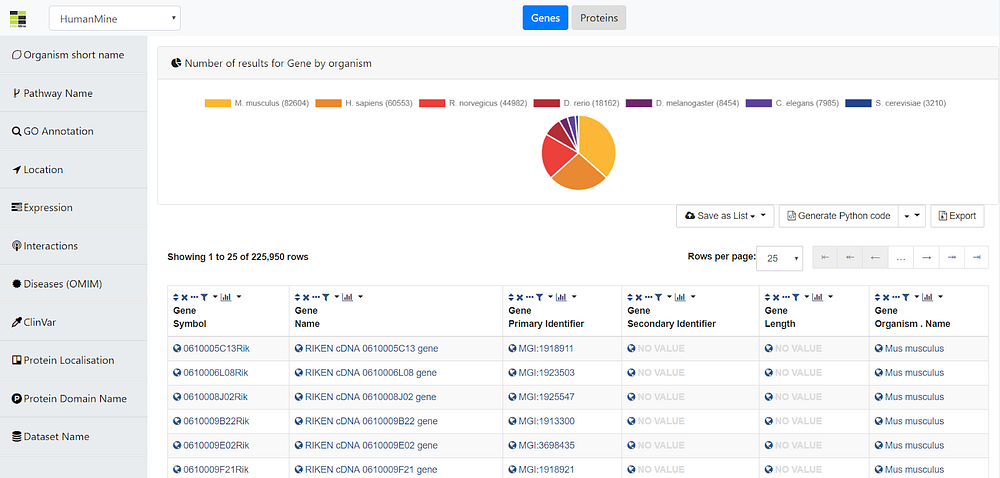
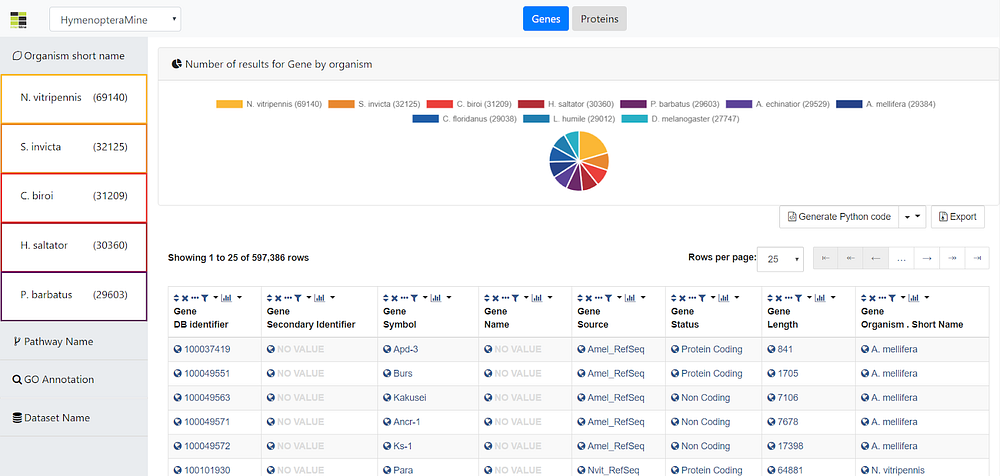
As depicted above, the user is able to change between the different mines available in the InterMine registry by using the dropdown box in (1). Next, in (2) the viewed class can be changed, and currently it can be either Genes or Proteins. Moreover, in (3), the different filters available in the currently explored mine are displayed, where the user can filter the data shown in the table at (6) that better fulfills his/her requirements. Furthermore, some plots regarding to the data in the table are displayed on (4). Currently it shows a pie chart of individuals per different organism, but it will be extended with more plots in the future. Finally, the user has the option to save the table as list, generate the code to embed it elsewhere, or to export the results by using the options in (5).
There are already some features to be added to the browser after GSoC, some of them are, for instance, to allow users to add their personal InterMine’s API tokens for each mine and use them for the Save as List functionality of the table (link). Another useful feature that I wasn’t able to implement due to a temporary disabling in the InterMine ontology was a Phenotypes filter (link). Next, a new histogram plot to the top section about Gene length will be added (link). Furthermore, a “current class” filter will be added to the sidebar (link). Finally, another desirable feature would be to refactor the per-mine filters to use path query (link).
As a conclusion, the fact that the final product has been tested and is going to be truly helpful for the target community of users, is enough for me to be proud of the developed tool during this Google Summer of Code. Also the results of this project will allow us to, hopefully, publish a paper describing the new InterMine browser.