
In order to keep InterMine updated to the latest technologies and integrated with the best solutions offered by the open source community, we always keep an eye on the emerging products and explore new tools/platforms. These days, our attention couldn’t not be caught by NoSQL databases.
What is NoSQL?
As the word says, NoSQL databases, refer, at least originally, to “non SQL” or “non relational” databases where the data are organised into one or more tables, however, most recently, the term NoSQL stands also for “not only SQL” because some tools have started introducing SQL-like query languages.
In NoSQL databases, there are many approaches to managing data using different structures:
key-value databases, the simplest NoSQL databases, where every single item is stored as an attribute name (or “key”), together with its value;
wide-column databases using tables, rows and columns, where the columns name and format can change from row to row within the same table;
document databases pairing each key with a complex data structure known as a document;
graph databases where the data are modeled into graphs, composed by nodes and edges (or “relations”).
As usual, there is no silver bullet and the best approach depends on the specific data model. So if we needed to implement a content management system or blogging platform, we would avoid using key-value databases, which are more suitable to store simple data (e.g. session information) and we’d be more inclined toward document databases.
In our specific case, because we have to handle complex biological data and relations, graph databases seem to be the most suitable candidate, worth considering as a possible alternative to the current relational database.
Experiment: InterMine + Neo4j
There are several open source implementations for graph databases; we have decided to start evaluating Neo4j, the most popular: very well established, good documentation, a big and active community supporting it, simple to use, regular meetups and events organized around the world.
The Neo4j Browser is a great tool to query data (using the simple Cypher language) and visualise them in different formats: graph, table, and text. In particular, the graph view is really neat and intuitive, in just few clicks you have a lot of information: clicking on any node or relationship you see the properties of that element and starting from a node you can expand all the relations associated to it. It is possible rearrange the graph, dragging or deleting nodes from the view, or to customize settings for colours, sizes and title nodes. Amazing!
Any time you run the Cypher queries in the editor at the top, the result is displayed in a new frame below; type another query, get another frame. Love it! And also the “history” command is so useful and persists across browser restarts. A really delightful and intuitive user interface.
But let us explain, in more detail, how the data are organized.
The Neo4j graphs are composed of nodes and relationships: the nodes, in general, represent the entities and they are connected by the relationships. Both of them can contain properties.
For example, the “zen” gene, represented as a row in the “gene” table in the current relational model, will be re-modeled as a node in the new graph model, and it’ll contain properties such as symbol, primaryidentifier, and secondaryidentifier. The same applies to the organism which the gene belongs to, it’s also now a node (in Postgres, organism is a separate table). The relationship PART_OF connects the gene node with its organism. Postgres requires a JOIN to query these two tables.

Relationships can also have properties: the fact that a gene is located in a specific position within the chromosome could be represented by the relationship LOCATED_ON with properties: start, end and strand.

Each node can have a label, so the node containing the gene will have label “Gene” and the node with the organism, the label “Organism”. Nice!
A node can have more than one label; so the node with genes will have labels: BioEntity, SequenceFeature, Gene. No more duplication of the same gene along the tables BioEntity, SequenceFeature, Gene, as we have in the current model, but just one node with several labels. This will save some database space, certainly.
Modelling the data
We have imported a part of FlyMine data into a new Neo4j database, using the Neo4j-shell tool and implementing new Cypher scripts.
Importing FlyMine data has been not only a necessary step before starting benchmarking, but also very useful to recognize the importance of re-thinking our data model.
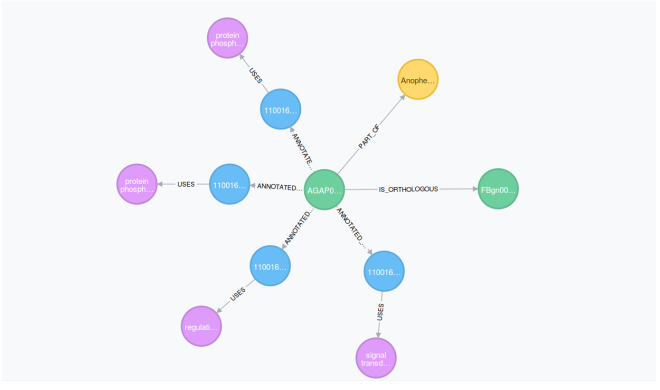
- Some associative tables have disappeared, replaced by relationships (e.g. the table genegoannotation has been replaced by the ANNOTATED_WITH relationship between the node Gene and the node GoAnnotation)
- Some tables have been replaced by multiple relationships (e.g. the table homologue has been substituted by the relations IS_ORTHOLOGOUS, IS_PARALOGOUS, and IS_LEAST_DIVERGED_ORTHOLOGOUS depending on the type) while the table’s columns have become a relationship’s properties (e.g. LOCATED_ON in the picture above)
- The view overlappingfeaturessequencefeature has been replaced by the OVERLAPS relationship between two genes.
Summary
These are just examples and maybe not the best approach to modelling our data, but they have helped us to imagine how our model could be represented in the Neo4j graph world and…we liked it!

Our first impressions of Neo4j have been very positive! We are very excited.
We are currently benchmarking the query execution times against PostgreSQL. We still have a lot of tuning and configuration settings to try out in order to obtain the best from Neo4j, which will be a challenge, but it is certainly worth the effort!
We will keep you updated.







 Only one statement represents the relation between the gene and the organism (that one containing the predicate hasOrganism), the others describe the properties of the two entities.
Only one statement represents the relation between the gene and the organism (that one containing the predicate hasOrganism), the others describe the properties of the two entities.

 As discussed in a previous post
As discussed in a previous post 

 We can not compare the complete queries exactly, but we can compare a simplified version of this. The table below shows the execution time to retrieve all the orthologues (and the organism which the orthologues belong to) of the gene with symbol “tws” but not the GO terms.
We can not compare the complete queries exactly, but we can compare a simplified version of this. The table below shows the execution time to retrieve all the orthologues (and the organism which the orthologues belong to) of the gene with symbol “tws” but not the GO terms.

You must be logged in to post a comment.